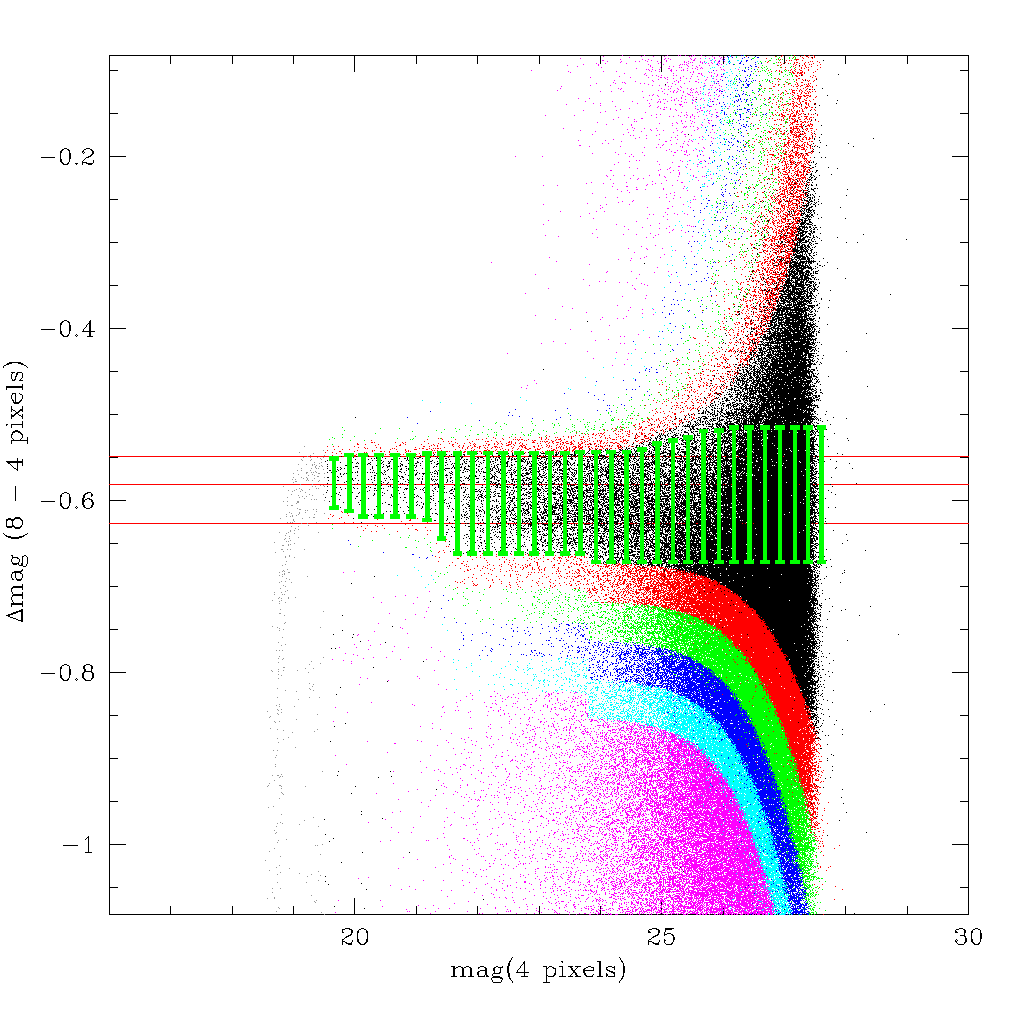
APS=(ΔMag-ΔMagcen)/(sqrt(σΔ2+σMag2))
The combined width (σΔ and M_ERR added in quadrature) is indicated on the plot at right by the green error bars. So the APS nnumber is effectively a probability that the object is stellar, with small (absolute) numbers corresponding to high probabilities that the souce is point-like.
Note that, when calculating the width of the stellar locus, bin sizes of 0.25 mags are used (or a minimum of 50 objects if the bin would contain less than 50 objects). Further, the width is calculated independantly above and below the position of the locus. Finally, the algorithm imposes additional constraint that the locus can never get thinner with fainter magnitudes, and that the width of the locus can never be more than twice the width calculated at bright magnitudes (to stop it blowing up at faint magnitudes).
This technique appears to work well to within approximately 1 magnitude of the completeness limits (ie to 24th magnitude or so). Below this, galaxies start being misidentified as stars.
In general, any objects within 1.5 sigma of the stellar locus in both filters have a very high probability of being stellar (modulo the caveat at faint magnitudes). Ultimately, inspection of the diagnostic plots, and the science case that is actually being addressed, will drive the selection criteria. The plot at right shows objects with different values of APS indicated by different colours:
| black | abs(APS)<1 |
| red | 1 <abs(APS)<1.5 |
| green | 1.5<abs(APS)<2 |
| blue | 2 <abs(APS)<2.5 |
| cyan | 2.5<abs(APS)<3 |
| magenta | 3 <abs(APS) |
In addition, in some fields you can see a sequence running parallel to the stellar sequence below the stellar sequence. These are globular clusters in Virgo, which are usually slightly more resolved than a star, and hence lie just below the stellar sequence. The APS value (Alan's Point Sourciness, named after Alan McConnachie) is computed for the g and i bands.